VisualDL 使用指南¶
概述¶
VisualDL 是一个面向深度学习任务设计的可视化工具。VisualDL 利用了丰富的图表来展示数据,用户可以更直观、清晰地查看数据的特征与变化趋势,有助于分析数据、及时发现错误,进而改进神经网络模型的设计。
目前,VisualDL 支持 scalar, image, audio,text, graph(动态图,静态图), histogram, pr curve, ROC curve, high dimensional, hyper parameters, profiler, x2paddle, fastdeployserver, fastdeployclient 共十五个组件,项目正处于高速迭代中,敬请期待新组件的加入。
| 组件名称 | 展示图表 | 作用 |
|---|---|---|
| Scalar | 折线图 | 动态展示损失函数值、准确率等标量数据 |
| Image | 图片可视化 | 显示图片,可显示输入图片和处理后的结果,便于查看中间过程的变化 |
| Audio | 音频可视化 | 播放训练过程中的音频数据,监控语音识别与合成等任务的训练过程 |
| Text | 文本可视化 | 展示文本任务任意阶段的数据输出,对比不同阶段的文本变化,便于深入了解训练过程及效果。 |
| Graph | 网络结构 | 展示网络结构、节点属性及数据流向,辅助学习、优化网络结构 |
| Histogram | 直方图 | 展示训练过程中权重、梯度等张量的分布 |
| PR Curve | 折线图 | 权衡精度与召回率之间的平衡关系 |
| ROC Curve | 折线图 | 展示不同阈值下的模型表现 |
| High Dimensional | 数据降维 | 将高维数据映射到 2D/3D 空间来可视化嵌入,便于观察不同数据的相关性 |
| Hyper Parameters | 超参数可视化 | 以丰富的视图多角度地可视化超参数与模型关键指标间的关系,便于快速确定最佳超参组合,实现高效调参。 |
| Profiler | 性能数据可视化 | 解析飞桨框架性能分析器导出的性能数据,辅助用户诊断训练程序性能瓶颈 |
| X2Paddle | 模型转换 | 展示onnx网络结构,并帮助用户转换为飞桨模型,提供转换后的模型结构和参数文件 |
| FastDeployServer | Serving可视化部署 | 提供对基于FastDeploy的Serving可视化部署,提供配置模型库、管理监控服务以及测试服务等功能 |
| FastDeployClient | Serving服务的客户端 | 提供对fastdeployserver服务进行访问的客户端界面 |
同时,VisualDL提供可视化结果保存服务,通过 VDL.service 生成链接,保存并分享可视化结果
Scalar--标量组件¶
介绍¶
Scalar 组件的输入数据类型为标量,该组件的作用是将训练参数以折线图形式呈现。将损失函数值、准确率等标量数据作为参数传入 scalar 组件,即可画出折线图,便于观察变化趋势。
记录接口¶
Scalar 组件的记录接口如下:
add_scalar(tag, value, step, walltime=None)
接口参数说明如下:
| 参数 | 格式 | 含义 |
| -------- | ------ | ------------------------------------------- |
| tag | string | 记录指标的标志,如train/loss,不能含有% |
| value | float | 要记录的数据值,不能为None |
| step | int | 记录的标量数据的步数,前端将抽取若干step对应的数据进行展示(VisualDL使用的采样算法为蓄水池采样,可参考VisualDL采样算法) |
| walltime | int | 记录数据的时间戳,默认为当前时间戳 |
*注意tag的使用规则为:
第一个
/前的为父tag,并作为一栏图片的tag第一个
/后的为子tag,子tag的对应图片将显示在父tag下,同一个父tag而不同子tag的数据将展示在一栏,但不是一张图中可以使用多次
/,但一栏图片的tag依旧为第一个/前的tag
具体使用参见以下三个例子:
创建train为父tag,acc和loss为子tag:
train/acc、train/loss,即创建了tag为train的图片栏,包含acc和loss两张图表:

创建train为父tag,test/acc和test/loss为子tag:
train/test/acc、train/test/loss,即创建了tag为train的图片栏,包含test/acc和test/loss两张图表:

创建两个父tag:
acc、loss,即创建了tag分别为acc和loss的两个图表栏::

Demo¶
基础使用
下面展示了使用 Scalar 组件记录数据的示例,代码见Scalar组件
from visualdl import LogWriter
if __name__ == '__main__':
value = [i/1000.0 for i in range(1000)]
# 初始化一个记录器
with LogWriter(logdir="./log/scalar_test/train") as writer:
for step in range(1000):
# 向记录器添加一个tag为`acc`的数据
writer.add_scalar(tag="acc", step=step, value=value[step])
# 向记录器添加一个tag为`loss`的数据
writer.add_scalar(tag="loss", step=step, value=1/(value[step] + 1))
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
接着在浏览器打开http://127.0.0.1:8080,即可查看以下折线图。

多组实验对比
下面展示了使用Scalar组件实现多组实验对比
多组实验对比的实现分为两步:
创建子日志文件储存每组实验的参数数据
将数据写入scalar组件时,使用相同的tag,即可实现对比不同实验的同一类型参数,这里注意想展示的日志文件必须放在不同的目录下,默认一个目录中只有一个日志文件有效且被展示
from visualdl import LogWriter
if __name__ == '__main__':
value = [i/1000.0 for i in range(1000)]
# 步骤一:创建父文件夹:log,子文件夹:scalar_test
with LogWriter(logdir="./log/scalar_test") as writer:
for step in range(1000):
# 步骤二:向记录器添加一个tag为`train/acc`的数据
writer.add_scalar(tag="train/acc", step=step, value=value[step])
# 步骤二:向记录器添加一个tag为`train/loss`的数据
writer.add_scalar(tag="train/loss", step=step, value=1/(value[step] + 1))
# 步骤一:创建第二个子文件夹:scalar_test2
value = [i/500.0 for i in range(1000)]
with LogWriter(logdir="./log/scalar_test2") as writer:
for step in range(1000):
# 步骤二:在同样名为`train/acc`下添加scalar_test2的accuracy的数据
writer.add_scalar(tag="train/acc", step=step, value=value[step])
# 步骤二:在同样名为`train/loss`下添加scalar_test2的loss的数据
writer.add_scalar(tag="train/loss", step=step, value=1/(value[step] + 1))
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
接着在浏览器打开http://127.0.0.1:8080,即可查看以下折线图,观察scalar_test和scalar_test2的accuracy和loss的对比。
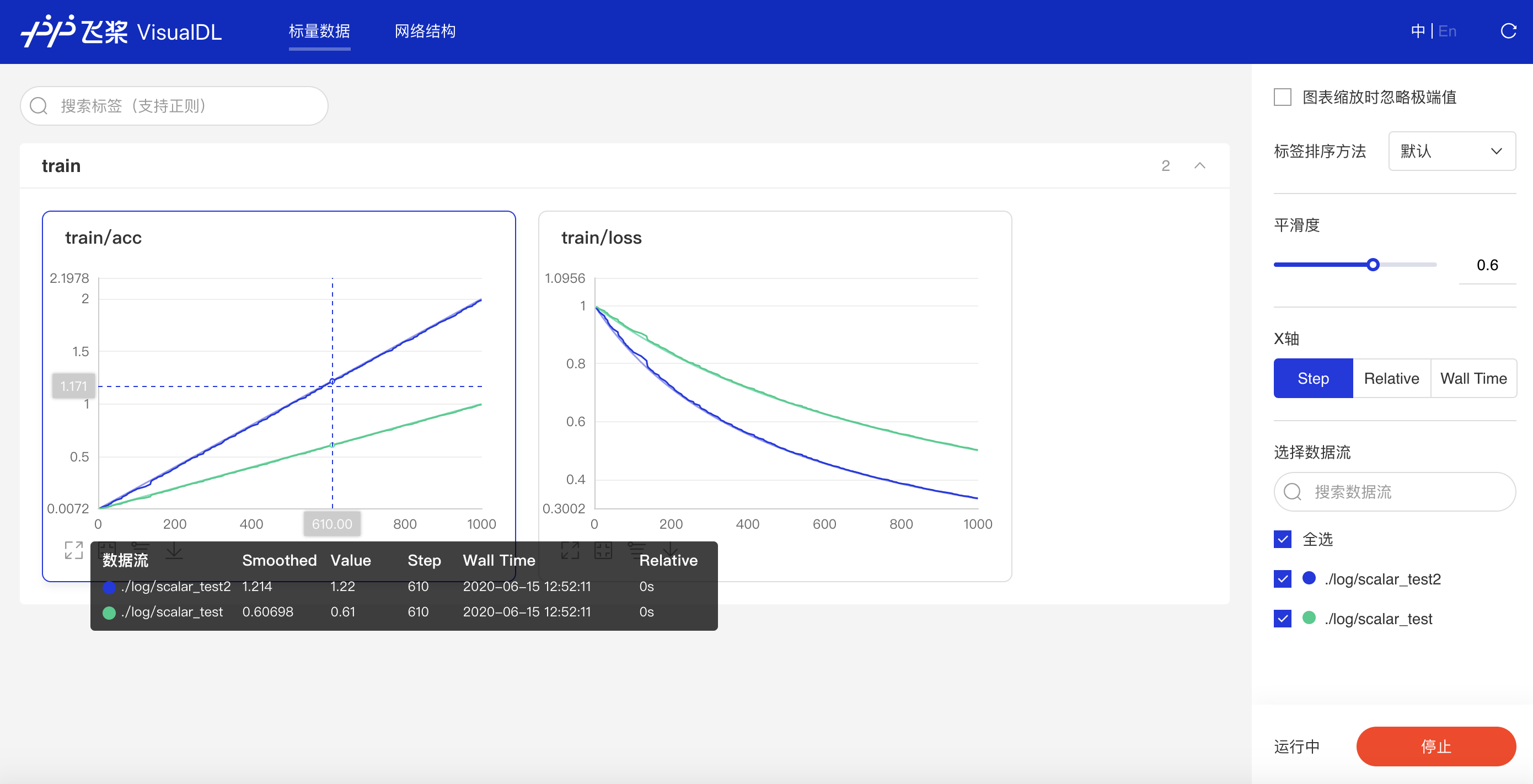
可以看出,不同实验(由路径决定)的数据在不同的图中展示,相同tag的数据在同一张图上展示,以便对比
*多组实验对比的应用案例可以参考AI Studio项目:VisualDL 2.0--眼疾识别训练可视化
功能操作说明¶
支持数据卡片「最大化」、「还原」、「坐标系转化」(y轴对数坐标)、「下载」折线图
![]()
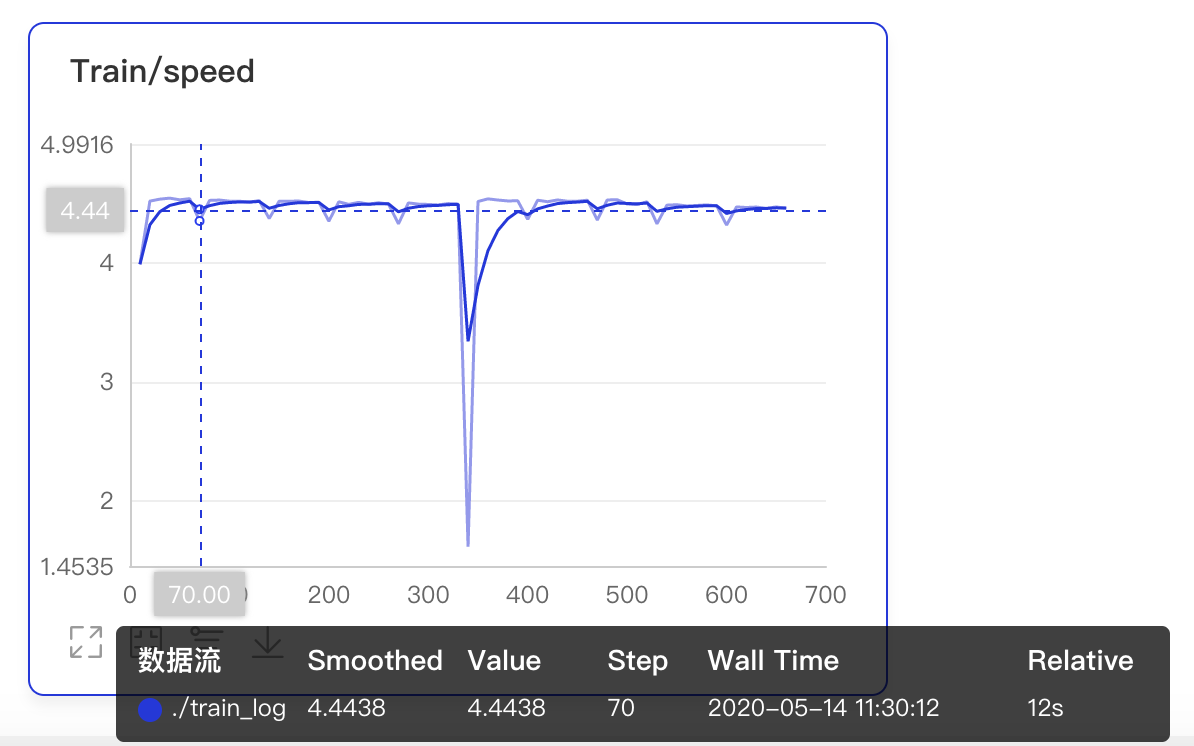
数据点Hover展示详细信息
可搜索卡片标签,展示目标图像
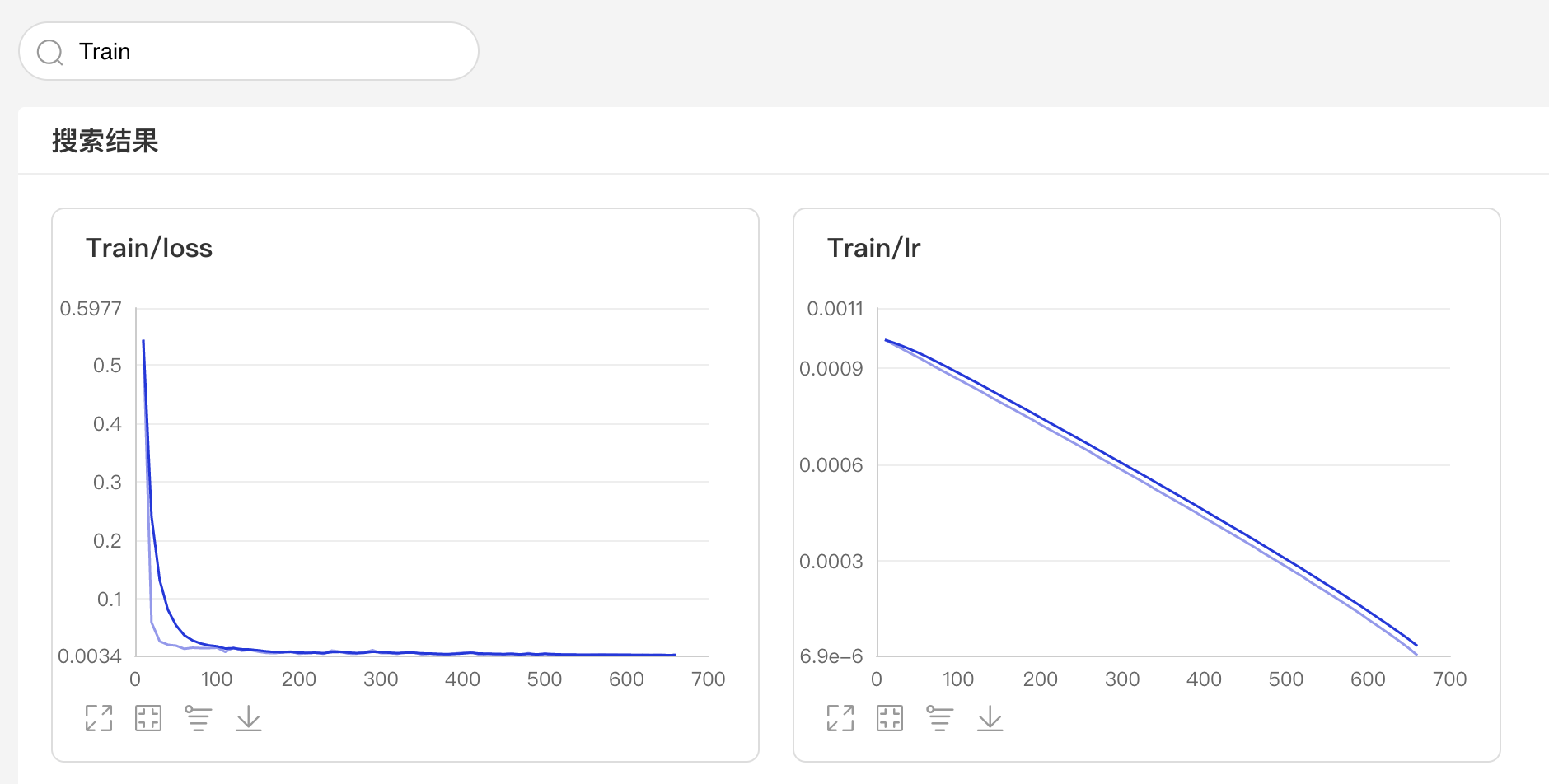
可搜索打点数据标签,展示特定数据

选择显示最值,展示最大最小值以及对应的训练步数


选择仅显示平滑后的数据


X轴有三种衡量尺度
Step:迭代次数
Walltime:训练绝对时间
Relative:训练时长

Image--图片可视化组件¶
介绍¶
Image 组件用于显示图片数据随训练的变化。在模型训练过程中,将图片数据传入 Image 组件,就可在 VisualDL 的前端网页查看相应图片。
记录接口¶
Image 组件的记录接口如下:
add_image(tag, img, step, walltime=None, dataformats="HWC")
接口参数说明如下:
| 参数 | 格式 | 含义 |
| -------- | ------------- | ------------------------------------------- |
| tag | string | 记录指标的标志,如train/loss,不能含有% |
| img | numpy.ndarray | 以ndarray格式表示的图片,默认HWC格式维度为[h, w, c],其中h和w代表图像的高度和宽度,c代表图像的通道数,可以为1、3、4,图像数据的浮点型数值会被归一化到[0, 1]。注意图片数据不能为None |
| step | int | 记录的图片数据步数 |
| walltime | int | 记录数据的时间戳,默认为当前时间戳 |
| dataformats| string | 传入的图片格式,包括NCHW、NHWC、HWC、CHW、HW,默认为HWC,在存储时会转化成HWC格式后继续存储|
Demo¶
下面展示了使用 Image 组件记录数据的示例,代码文件请见Image组件
import numpy as np
from PIL import Image
from visualdl import LogWriter
def random_crop(img):
"""获取图片的随机 100x100 分片
"""
img = Image.open(img)
w, h = img.size
random_w = np.random.randint(0, w - 100)
random_h = np.random.randint(0, h - 100)
# 生成HWC格式的图片
r = img.crop((random_w, random_h, random_w + 100, random_h + 100))
return np.asarray(r)
if __name__ == '__main__':
# 初始化一个记录器
with LogWriter(logdir="./log/image_test/train") as writer:
for step in range(6):
# 添加一个图片数据
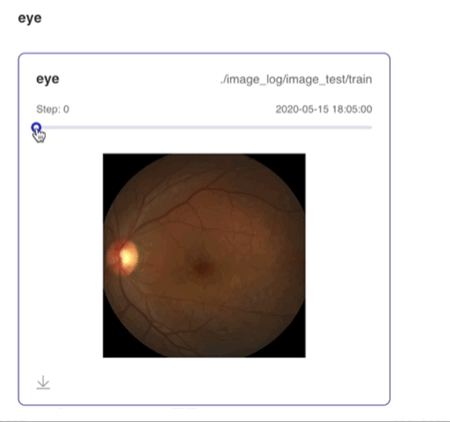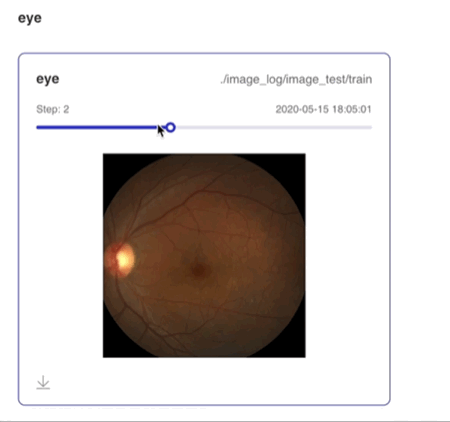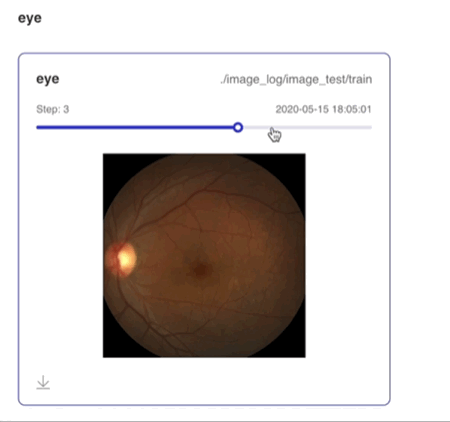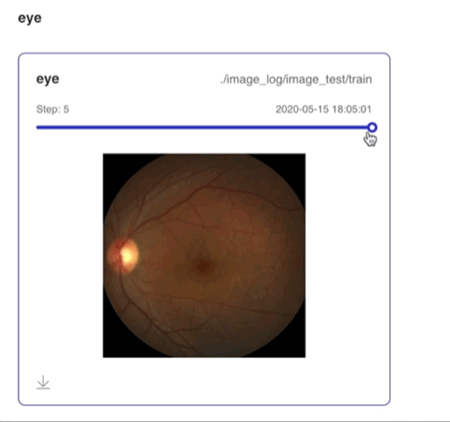
writer.add_image(tag="eye",
img=random_crop("../../docs/images/eye.jpg"),
step=step)
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
在浏览器输入http://127.0.0.1:8080,即可查看图片数据。

功能操作说明¶
可搜索图片标签显示对应图片数据
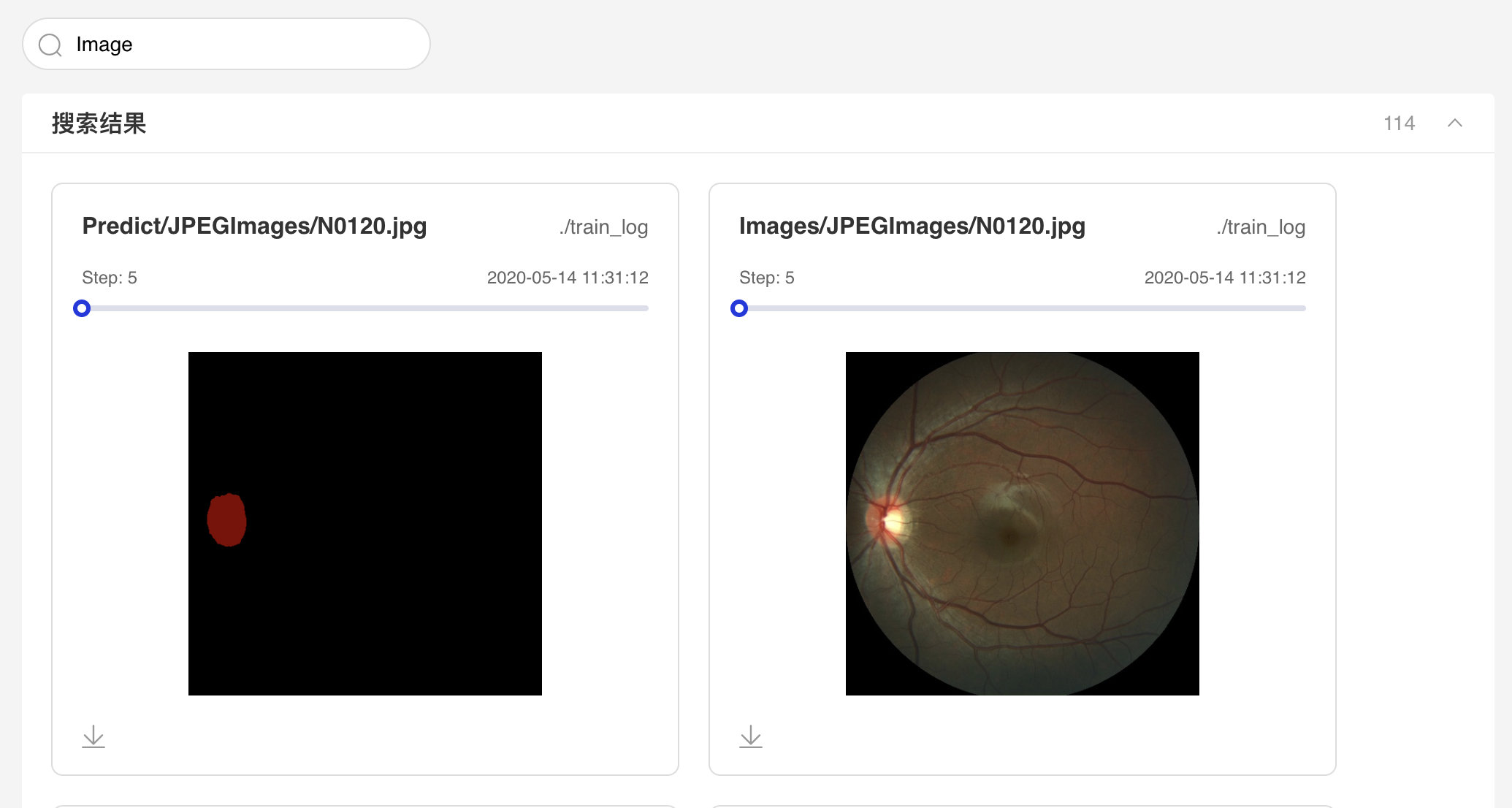
支持滑动Step/迭代次数查看不同迭代次数下的图片数据
添加图片矩阵¶
除使用add_image记录一张图片之外,还可以使用add_image_matrix一次添加多张图片并生成一张图片矩阵,接口及参数说明如下: add_image_matrix的记录接口如下:
add_image_matrix(tag, imgs, step, rows=-1, scale=1, walltime=None, dataformats="HWC")
接口参数说明如下:
| 参数 | 格式 | 含义 |
| -------- | ------------- | ------------------------------------------- |
| tag | string | 记录指标的标志,如train/loss,不能含有% |
| imgs | numpy.ndarray | 以ndarray格式表示的多张图片,第一维为图片的数量,其他维度表示一张图片,根据其格式具有不同的维度,默认HWC格式维度为[h, w, c]其中c可以为1、3、4,注意图片数据不能为None |
| step | int | 记录的图片矩阵的步数 |
| rows | int | 生成图片矩阵的行数,默认值为-1,表示尽量把传入的图片组合成行列数相近的形式,否则将自动将图片排列按照rows进行重新组织 |
| scale | int | 图片放大比例,默认为1,放大缩小图片可能造成图片像素缺失 |
| walltime | int | 记录数据的时间戳,默认为当前时间戳 |
| dataformats| string | 传入的图片格式,包括NCHW、NHWC、HWC、HW,默认为HWC,在存储时会转化成HWC格式后继续存储|
PS:当给定的子图像数量不足时,默认将用空白图像填充,以保证生成的图形为完整矩形
Demo¶
下面展示了使用 Image 组件合成并记录多张图片数据的示例,代码文件请见Image组件
import numpy as np
from PIL import Image
from visualdl import LogWriter
if __name__ == '__main__':
imgs = []
for index in range(6):
imgs.append(np.asarray(Image.open("../../docs/images/images_matrix/%s.jpg" % str((index)))))
with LogWriter(logdir='./log/image_matrix_test/train') as writer:
# 使用add_image记录单张图片
writer.add_image(tag='detection', step=0, img=imgs[0])
# 合成长宽尽量接近的图形矩阵,本例生成3X2的矩阵
writer.add_image_matrix(tag='detection', step=1, imgs=imgs, rows=-1)
# 合成长为1的图形矩阵,本例生成1x6的矩阵
writer.add_image_matrix(tag='detection', step=2, imgs=imgs, rows=1)
# 合成长为2的图形矩阵,本例生成2X3的矩阵
writer.add_image_matrix(tag='detection', step=3, imgs=imgs, rows=2)
# 合成长为3的图形矩阵,本例生成3X2的矩阵
writer.add_image_matrix(tag='detection', step=4, imgs=imgs, rows=3)
# 合成长为4的图形矩阵,本例生成4X2的矩阵,自动补充子图像填充第四行
writer.add_image_matrix(tag='detection', step=5, imgs=imgs, rows=4)
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
在浏览器输入http://127.0.0.1:8080,即可查看图片数据。


Audio--音频播放组件¶
介绍¶
Audio组件实时查看训练过程中的音频数据,监控语音识别与合成等任务的训练过程。
记录接口¶
Audio 组件的记录接口如下:
add_audio(tag, audio_array, step, sample_rate)
接口参数说明如下:
| 参数 | 格式 | 含义 |
| -------- | ------------- | ------------------------------------------- |
| tag | string | 记录指标的标志,如audio_tag,不能含有% |
| audio_arry | numpy.ndarray | 以ndarray格式表示的音频,其元素为float值,范围应归一化到[-1, 1] |
| step | int | 记录的音频数据步数 |
| sample_rate | int | 采样率,默认采样率为8000,注意正确填写对应音频的采样率 |
Demo¶
下面展示了使用 Audio 组件记录数据的示例,代码文件请见Audio组件
from visualdl import LogWriter
from scipy.io import wavfile
if __name__ == '__main__':
with LogWriter(logdir="./log/audio_test/train") as writer:
sample_rate, audio_data = wavfile.read('./test.wav')
writer.add_audio(tag="audio_tag",
audio_array=audio_data,
step=0,
sample_rate=sample_rate)
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
在浏览器输入http://127.0.0.1:8080,即可查看音频数据。
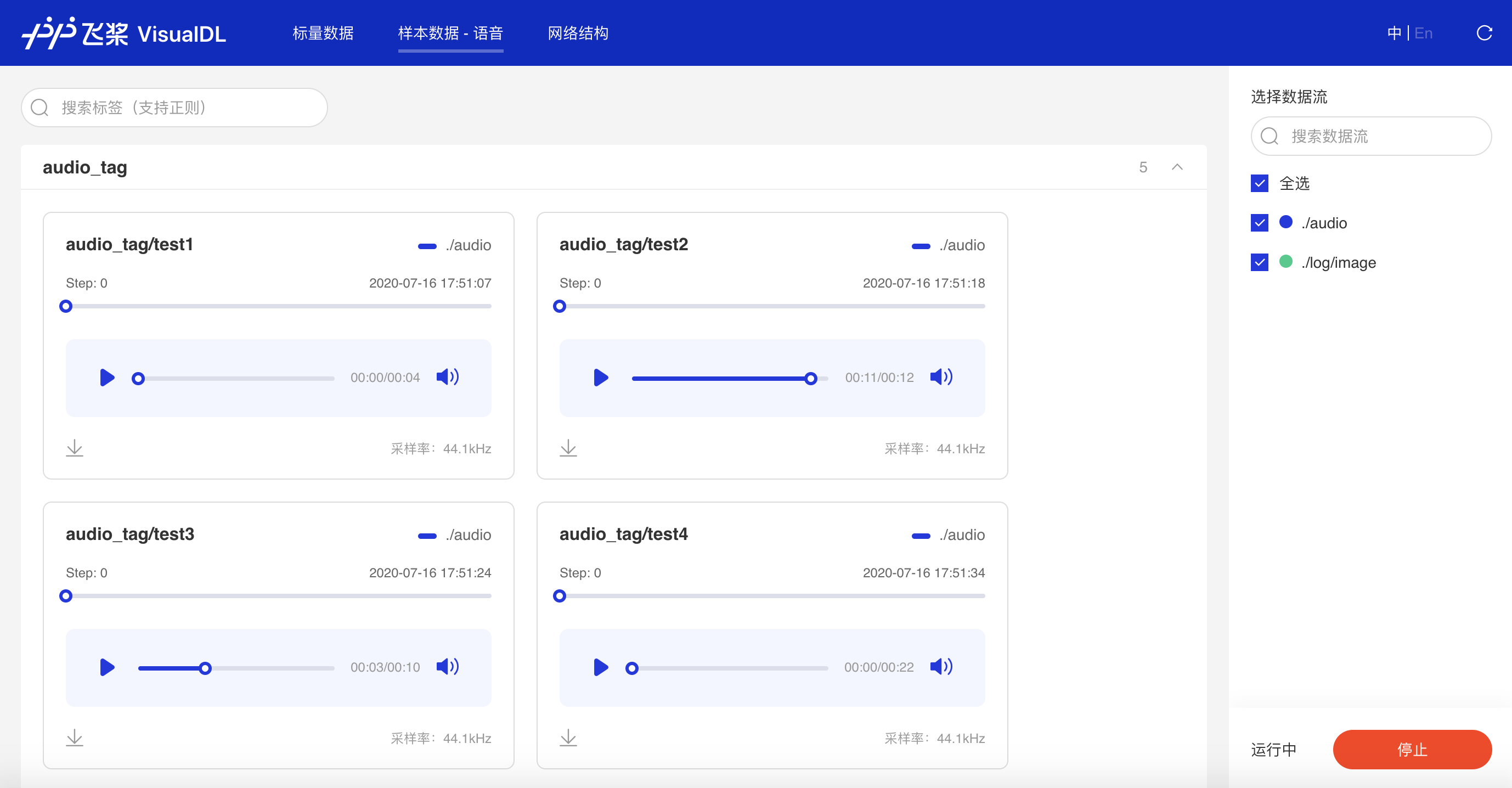
功能操作说明¶
可搜索音频标签显示对应音频数据
支持滑动Step/迭代次数查看不同迭代次数下的音频数据
支持播放/暂停音频数据
支持音量调节
支持音频下载
Text--文本组件¶
介绍¶
Text展示文本任务任意阶段的数据输出,对比不同阶段的文本变化,便于深入了解训练过程及效果。
记录接口¶
Text组件的记录接口如下:
add_text(tag, text_string, step=None, walltime=None)
接口参数说明如下:
| 参数 | 格式 | 含义 |
|---|---|---|
| tag | string | 记录指标的标志,如train/loss,不能含有% |
| text_string | string | 文本字符串 |
| step | int | 记录的文本步数 |
| walltime | int | 记录数据的时间戳,默认为当前时间戳 |
Demo¶
下面展示了使用 Text 组件记录数据的示例,代码见Text组件
from visualdl import LogWriter
if __name__ == '__main__':
texts = [
'上联: 众 佛 群 灵 光 圣 地 下联: 众 生 一 念 证 菩 提',
'上联: 乡 愁 何 处 解 下联: 故 事 几 时 休',
'上联: 清 池 荷 试 墨 下联: 碧 水 柳 含 情',
'上联: 既 近 浅 流 安 笔 砚 下联: 欲 将 直 气 定 乾 坤',
'上联: 日 丽 萱 闱 祝 无 量 寿 下联: 月 明 桂 殿 祝 有 余 龄',
'上联: 一 地 残 红 风 拾 起 下联: 半 窗 疏 影 月 窥 来'
]
with LogWriter(logdir="./log/text_test/train") as writer:
for step in range(len(texts)):
writer.add_text(tag="output", step=step, text_string=texts[step])
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
接着在浏览器打开http://127.0.0.1:8080,即可查看Text

功能操作说明¶
可搜索文本标签显示对应文本数据

可搜索数据流标签显示对应数据流数据

可折叠标签

Graph--网络结构组件¶
介绍¶
Graph组件一键可视化模型的网络结构。用于查看模型属性、节点信息、节点输入输出等,并进行节点搜索,协助开发者们快速分析模型结构与了解数据流向,覆盖动态图与静态图两种格式。
记录接口¶
Graph组件的记录接口如下:
add_graph(model, input_spec, verbose=False):
接口参数说明如下:
| 参数 | 格式 | 含义 |
|---|---|---|
| model | paddle.nn.Layer | Paddle的动态图模型 |
| input_spec | list[paddle.static.InputSpec|Tensor] | 用于描述模型输入的参数 |
| verbose | bool | 是否在终端打印模型的节点统计信息 |
注意
使用add_graph接口需要安装飞桨paddlepaddle, 安装步骤请参考飞桨官方网站。
Demo¶
下面展示了使用 Graph 组件记录飞桨动态图模型的示例,代码见Graph组件
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from visualdl import LogWriter
class MyNet(nn.Layer):
def __init__(self):
super(MyNet, self).__init__()
self.conv1 = nn.Conv2D(
in_channels=1, out_channels=20, kernel_size=5, stride=1, padding=2)
self.max_pool1 = nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = nn.Conv2D(
in_channels=20,
out_channels=20,
kernel_size=5,
stride=1,
padding=2)
self.max_pool2 = nn.MaxPool2D(kernel_size=2, stride=2)
self.fc = nn.Linear(in_features=980, out_features=10)
def forward(self, inputs):
x = self.conv1(inputs)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc(x)
return x
net = MyNet()
with LogWriter(logdir="./log/graph_test/") as writer:
writer.add_graph(
model=net,
input_spec=[paddle.static.InputSpec([-1, 1, 28, 28], 'float32')],
verbose=True)
运行上述程序后,在命令行执行
visualdl --logdir ./log/graph_test/ --port 8080
接着在浏览器打开http://127.0.0.1:8080,即可查看Graph
启动后即可查看飞桨动态图网络结构可视化:

注意
VisualDL之前的版本支持通过--model参数直接指定模型结构文件,现在仍然保持这一选项,
通过add_graph接口导出的动态图模型文件(文件名包含"vdlgraph"), 在动态图页面展示,
并在页面中以'manual_input_model'来表示通过该参数指定的模型。其余所支持的文件格式在静态图页面中展示。
例如
visualdl --model ./log/model.pdmodel --port 8080
将展示在静态图页面。
visualdl --model ./log/vdlgraph.1655783158.log --port 8080
将展示在动态图页面。
功能操作说明¶
当前Graph页面分为动态图和静态图两个页面。其中动态图页面用来展示通过add_graph接口导出的飞桨动态图模型结构,静态图页面用来展示飞桨静态图模型结构(通过飞桨的paddle.jit.save导出的后缀名为pdmodel的文件)及其它可支持框架的模型。

通用功能:
支持上下左右任意拖拽模型、放大和缩小模型

搜索定位到对应节点

点击查看模型属性

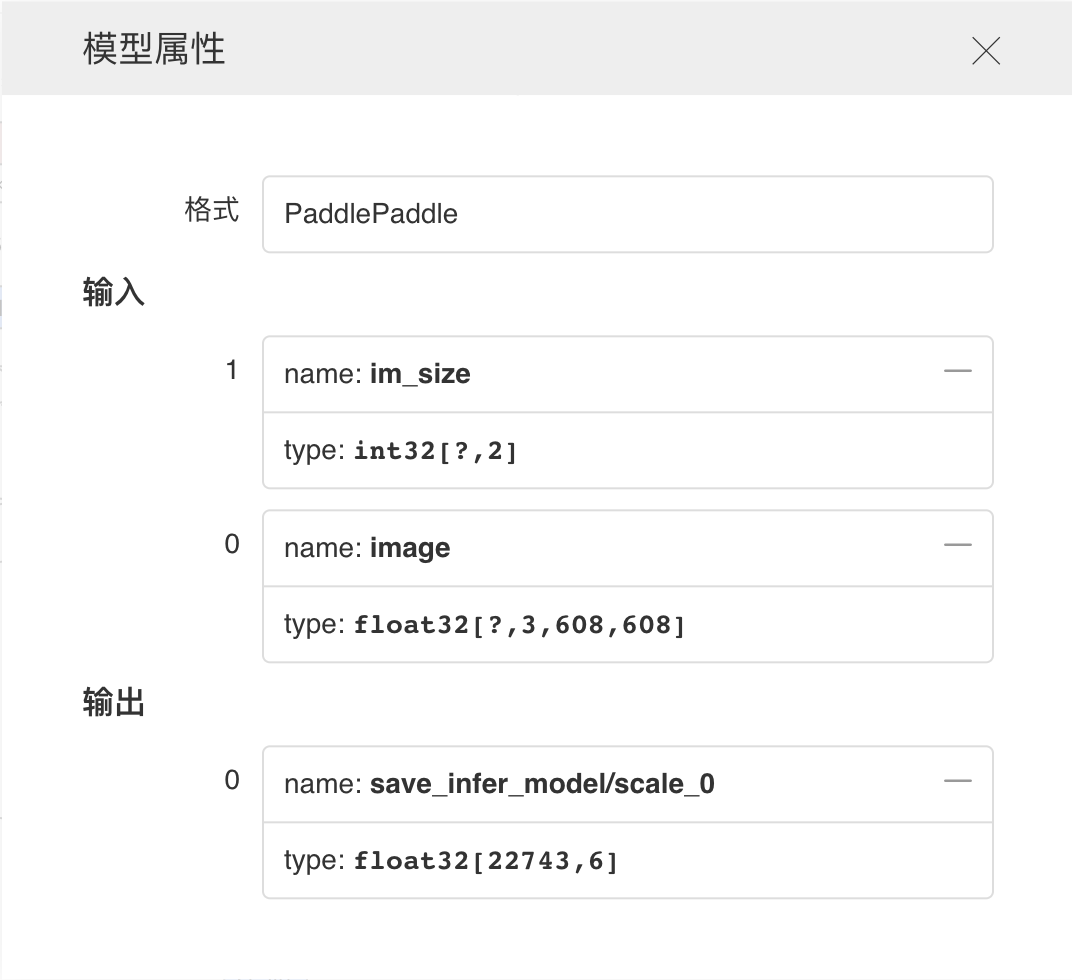
支持选择模型展示的信息

支持以PNG、SVG格式导出文件

点击节点即可展示对应属性信息
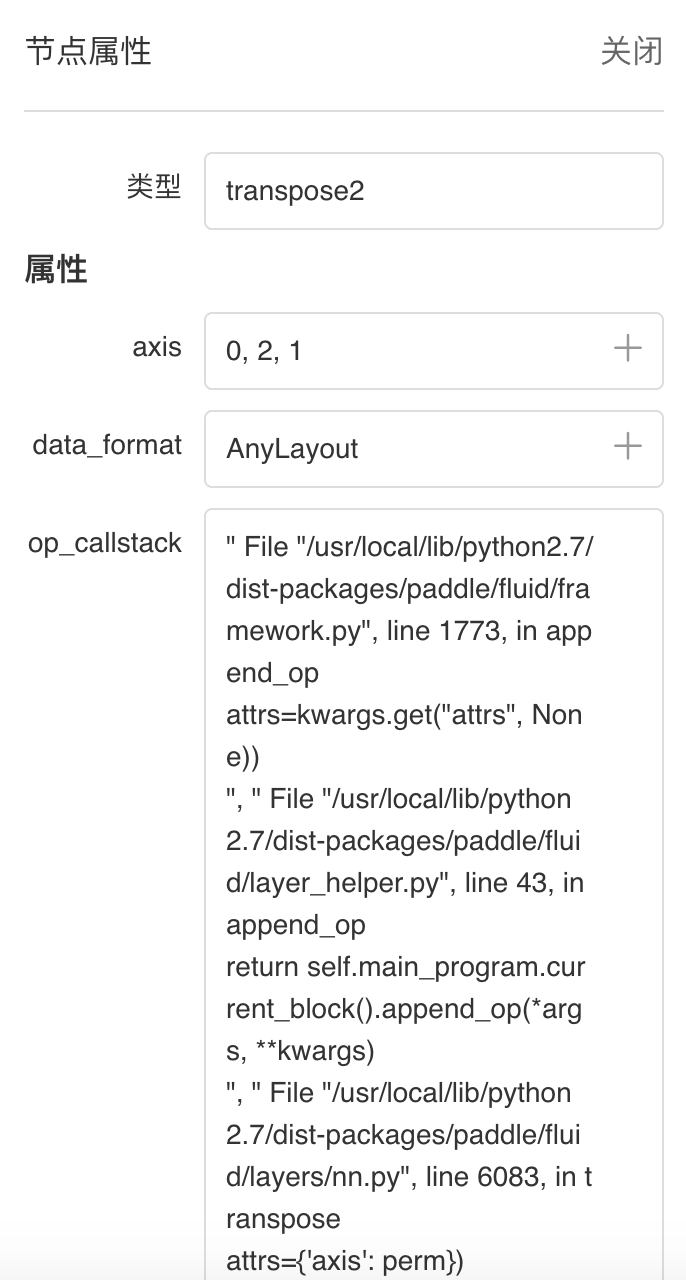
支持一键更换模型

动态图页面特有功能:
展开和折叠指定节点


一键全展开和全折叠


飞桨API链接功能
对于使用paddle.nn中的组件搭建的节点,可以使用alt+鼠标点击的方式跳转到官网的API说明文档。


静态图页面特有功能:
一键上传模型
支持模型格式:PaddlePaddle、ONNX、Keras、Core ML、Caffe、Caffe2、Darknet、MXNet、ncnn、TensorFlow Lite
实验性支持模型格式:TorchScript、PyTorch、Torch、 ArmNN、BigDL、Chainer、CNTK、Deeplearning4j、MediaPipe、ML.NET、MNN、OpenVINO、Scikit-learn、Tengine、TensorFlow.js、TensorFlow

Histogram--直方图组件¶
介绍¶
Histogram组件以直方图形式展示Tensor(weight、bias、gradient等)数据在训练过程中的变化趋势。深入了解模型各层效果,帮助开发者精准调整模型结构。
记录接口¶
Histogram 组件的记录接口如下:
add_histogram(tag, values, step, walltime=None, buckets=10)
接口参数说明如下:
| 参数 | 格式 | 含义 |
| -------- | --------------------- | ------------------------------------------- |
| tag | string | 记录指标的标志,如train/loss,不能含有% |
| values | numpy.ndarray or list | 以ndarray或list格式表示的数据,其维度为(N, ) |
| step | int | 记录的直方图步数 |
| walltime | int | 记录数据的时间戳,默认为当前时间戳 |
| buckets | int | 生成直方图的分段数,默认为10 |
Demo¶
下面展示了使用 Histogram组件记录数据的示例,代码见Histogram组件
from visualdl import LogWriter
import numpy as np
if __name__ == '__main__':
values = np.arange(0, 1000)
with LogWriter(logdir="./log/histogram_test/train") as writer:
for index in range(1, 101):
interval_start = 1 + 2 * index / 100.0
interval_end = 6 - 2 * index / 100.0
data = np.random.uniform(interval_start, interval_end, size=(10000))
writer.add_histogram(tag='default tag',
values=data,
step=index,
buckets=10)
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
在浏览器输入http://127.0.0.1:8080,即可查看训练参数直方图。
功能操作说明¶
支持数据卡片「最大化」、「下载」直方图
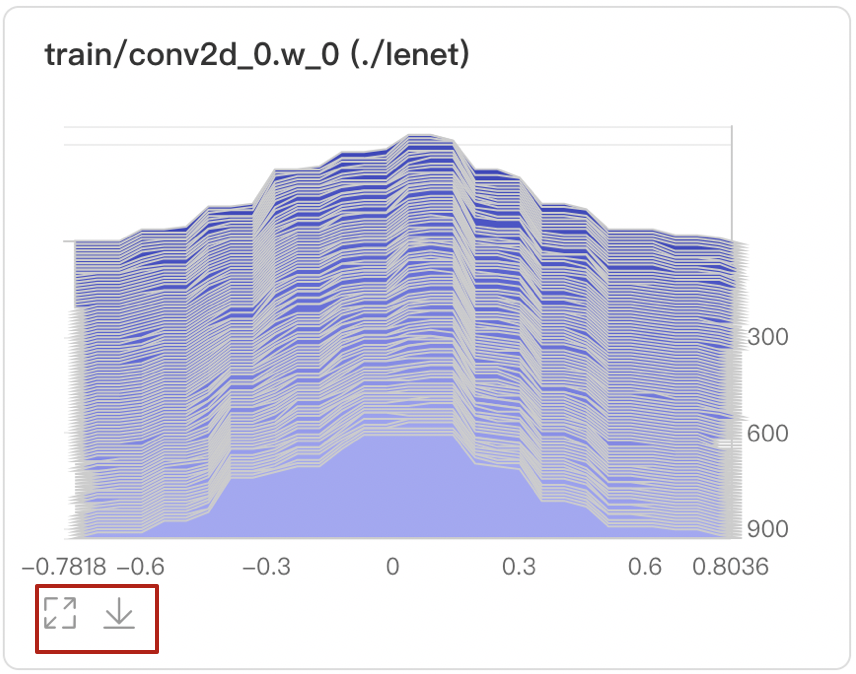
可选择Offset或Overlay模式

Offset模式
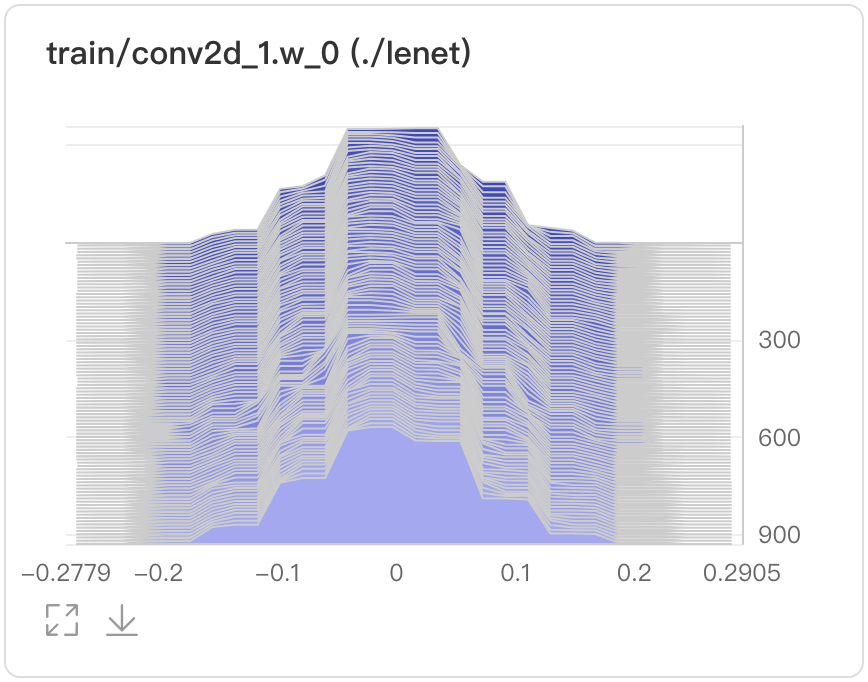
Overlay模式
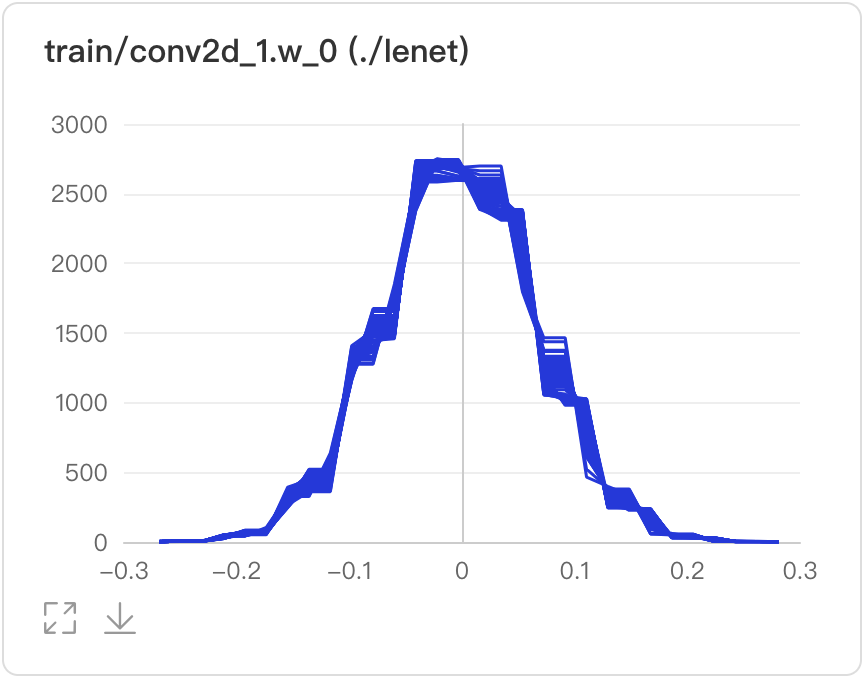
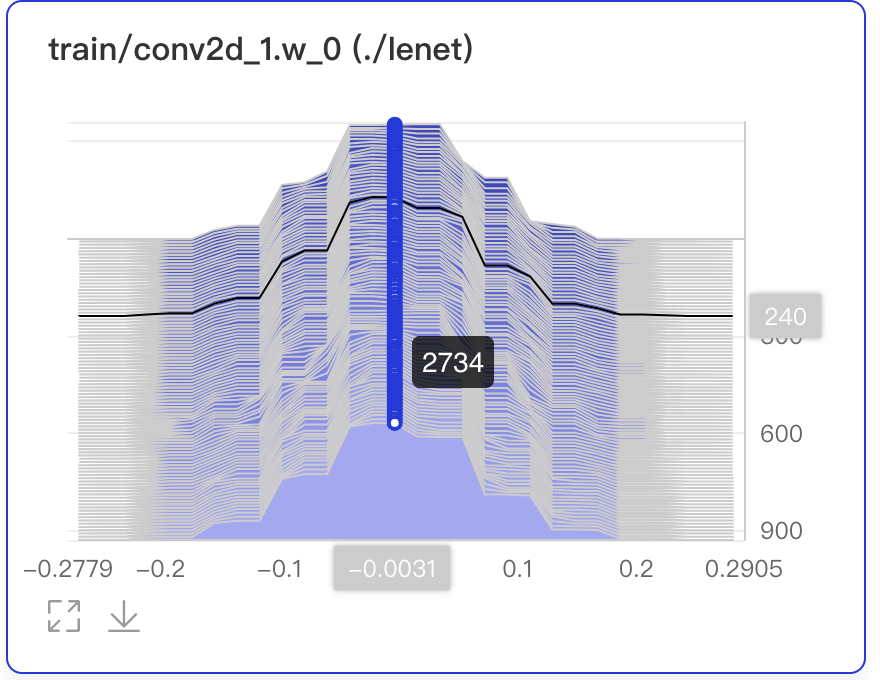
数据点Hover展示参数值、训练步数、频次
在第240次训练步数时,权重为-0.0031,且出现的频次是2734次
可搜索卡片标签,展示目标直方图
可搜索打点数据标签,展示特定数据流

PR Curve--PR曲线组件¶
介绍¶
PR Curve以折线图形式呈现精度与召回率的权衡分析,清晰直观了解模型训练效果,便于分析模型是否达到理想标准。
记录接口¶
PR Curve组件的记录接口如下:
add_pr_curve(tag, labels, predictions, step=None, num_thresholds=10)
接口参数说明如下:
| 参数 | 格式 | 含义 |
|---|---|---|
| tag | string | 记录指标的标志,如train/loss,不能含有% |
| labels | numpy.ndarray or list | 以ndarray或list格式表示的实际类别,维度为(N, ),值为0或1 |
| predictions | numpy.ndarray or list | 以ndarray或list格式表示的预测类别,维度为(N, ),值的范围应该在[0, 1] |
| step | int | 记录的pr curve曲线步数 |
| num_thresholds | int | 阈值设置的个数,默认为10,最大值为127 |
| weights | float | 用于设置TP/FP/TN/FN在计算precision和recall时的权重 |
| walltime | int | 记录数据的时间戳,默认为当前时间戳 |
Demo¶
下面展示了使用 PR Curve 组件记录数据的示例,代码见PR Curve组件
from visualdl import LogWriter
import numpy as np
# 生成一个日志记录器
with LogWriter("./log/pr_curve_test/train") as writer:
for step in range(3):
labels = np.random.randint(2, size=100)
predictions = np.random.rand(100)
# 添加一条pr curve曲线数据
writer.add_pr_curve(tag='pr_curve',
labels=labels,
predictions=predictions,
step=step,
num_thresholds=5)
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
接着在浏览器打开http://127.0.0.1:8080,即可查看PR Curve
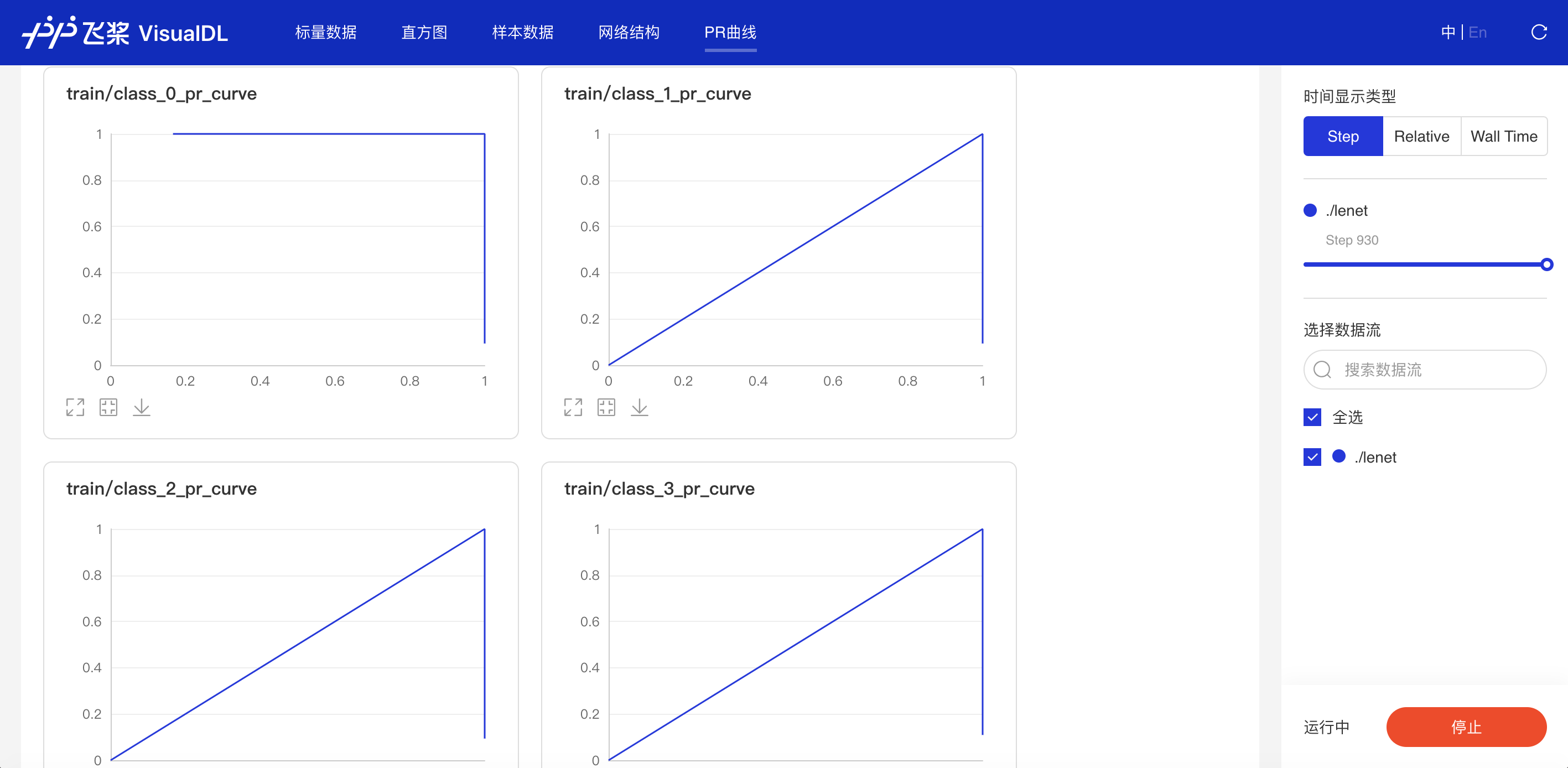
功能操作说明¶
支持数据卡片「最大化」、「还原」、「下载」PR曲线
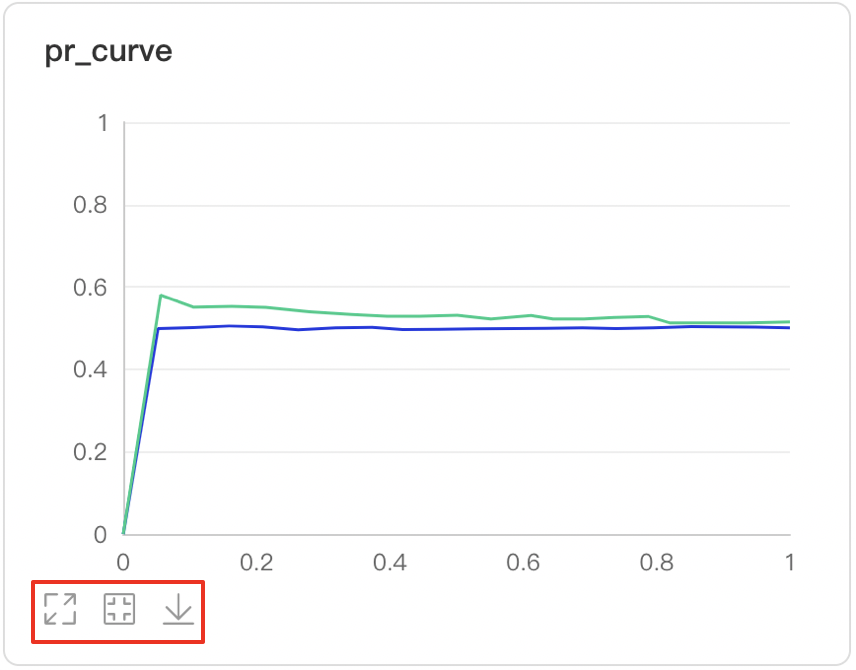
数据点Hover展示详细信息:阈值对应的TP、TN、FP、FN
可搜索卡片标签,展示目标图表

可搜索打点数据标签,展示特定数据

支持查看不同训练步数下的PR曲线

X轴-时间显示类型有三种衡量尺度
Step:迭代次数
Walltime:训练绝对时间
Relative:训练时长

ROC Curve--ROC曲线组件¶
介绍¶
ROC曲线展示不同阈值下模型指标的变化,同时曲线下的面积(AUC)直观的反应模型表现,辅助开发者掌握模型训练情况并高效进行阈值选择。
记录接口¶
ROC Curve组件的记录接口如下:
add_roc_curve(tag, labels, predictions, step=None, num_thresholds=10)
接口参数说明如下:
| 参数 | 格式 | 含义 |
|---|---|---|
| tag | string | 记录指标的标志,如train/loss,不能含有% |
| labels | numpy.ndarray or list | 以ndarray或list格式表示的实际类别,维度为(N, ),值为0或1 |
| predictions | numpy.ndarray or list | 以ndarray或list格式表示的预测类别,维度为(N, ),值的范围应该在[0, 1] |
| step | int | 记录的roc curve曲线的步数 |
| num_thresholds | int | 阈值设置的个数,默认为10,最大值为127 |
| weights | float | 用于设置TP/FP/TN/FN在计算precision和recall时的权重 |
| walltime | int | 记录数据的时间戳,默认为当前时间戳 |
Demo¶
下面展示了使用 ROC Curve 组件记录数据的示例,代码见ROC Curve组件
from visualdl import LogWriter
import numpy as np
# 生成一个日志记录器
with LogWriter("./log/roc_curve_test/train") as writer:
for step in range(3):
labels = np.random.randint(2, size=100)
predictions = np.random.rand(100)
# 添加一条roc数据
writer.add_roc_curve(tag='roc_curve',
labels=labels,
predictions=predictions,
step=step,
num_thresholds=5)
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
接着在浏览器打开http://127.0.0.1:8080,即可查看ROC Curve
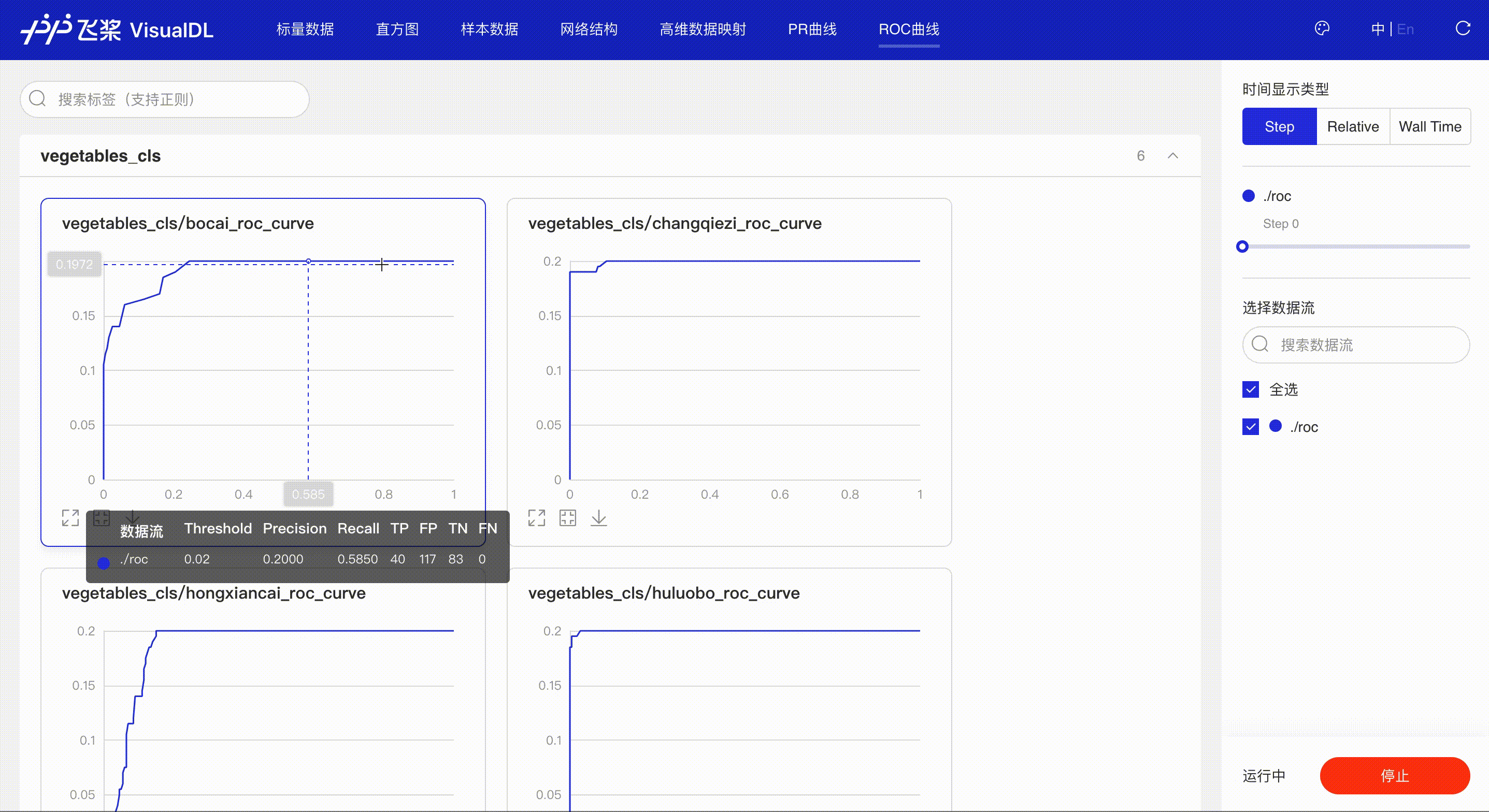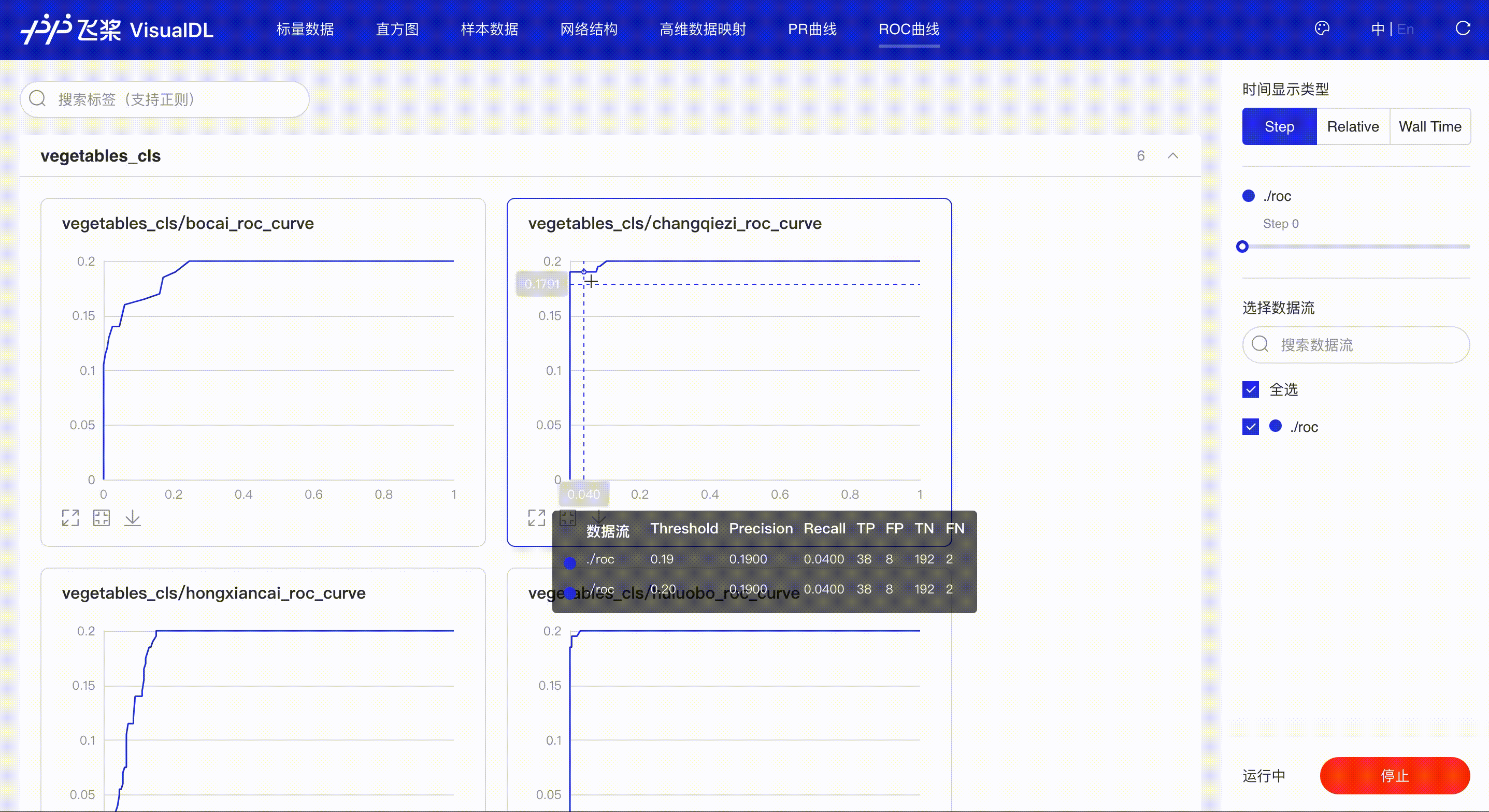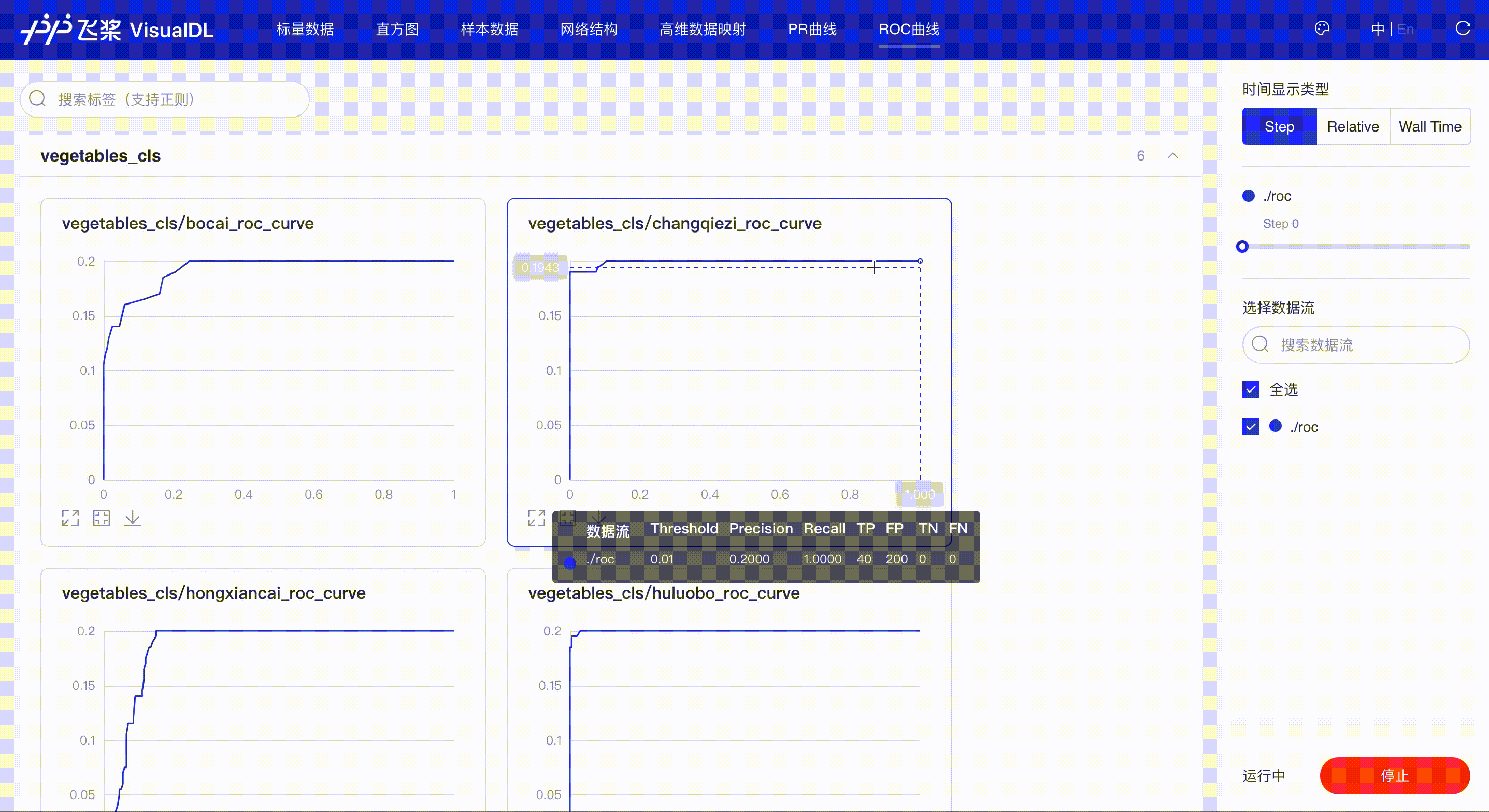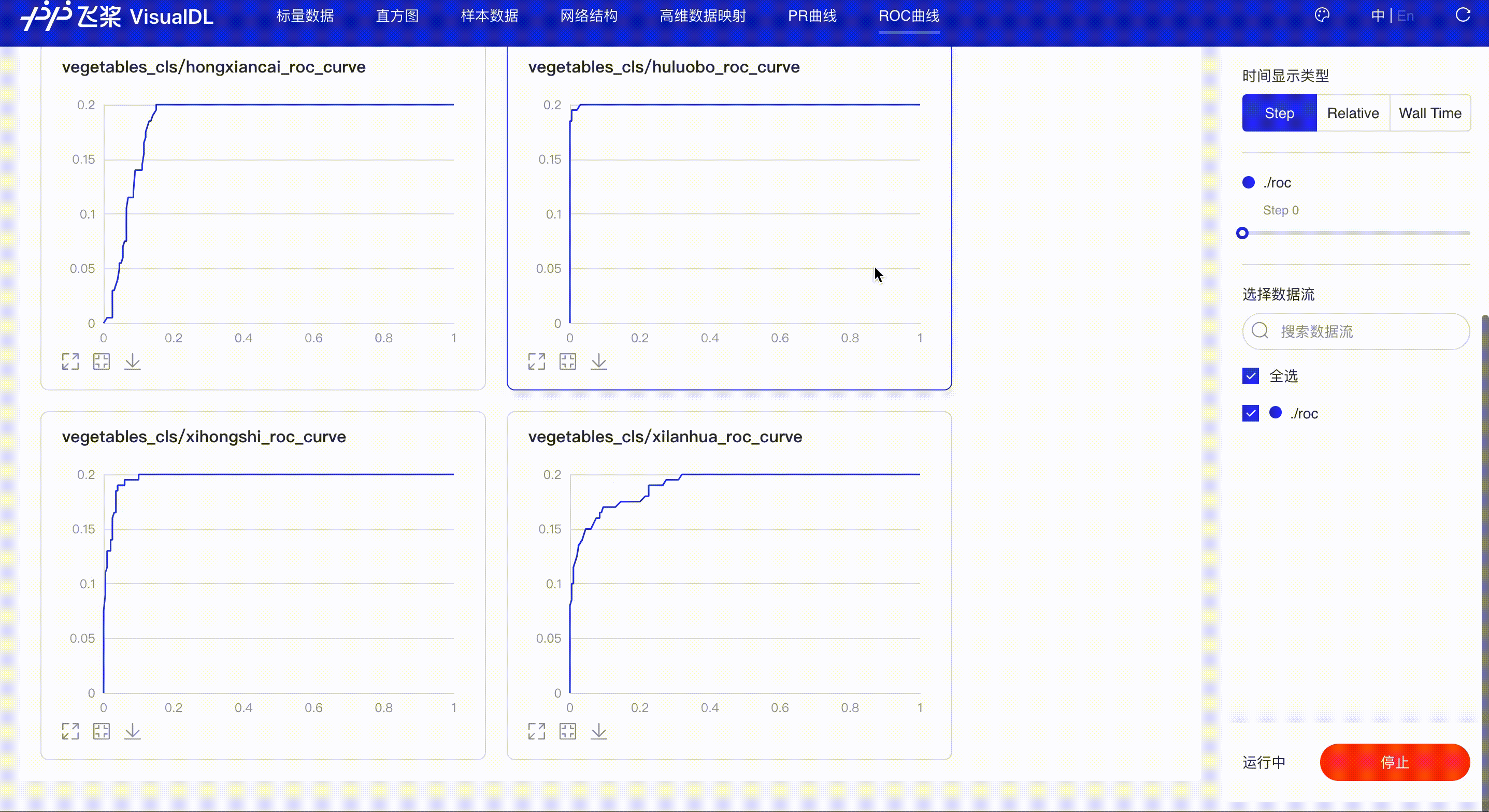
*Note:ROC前端页面使用和PR相同,请参考上述PR Curve的使用说明。
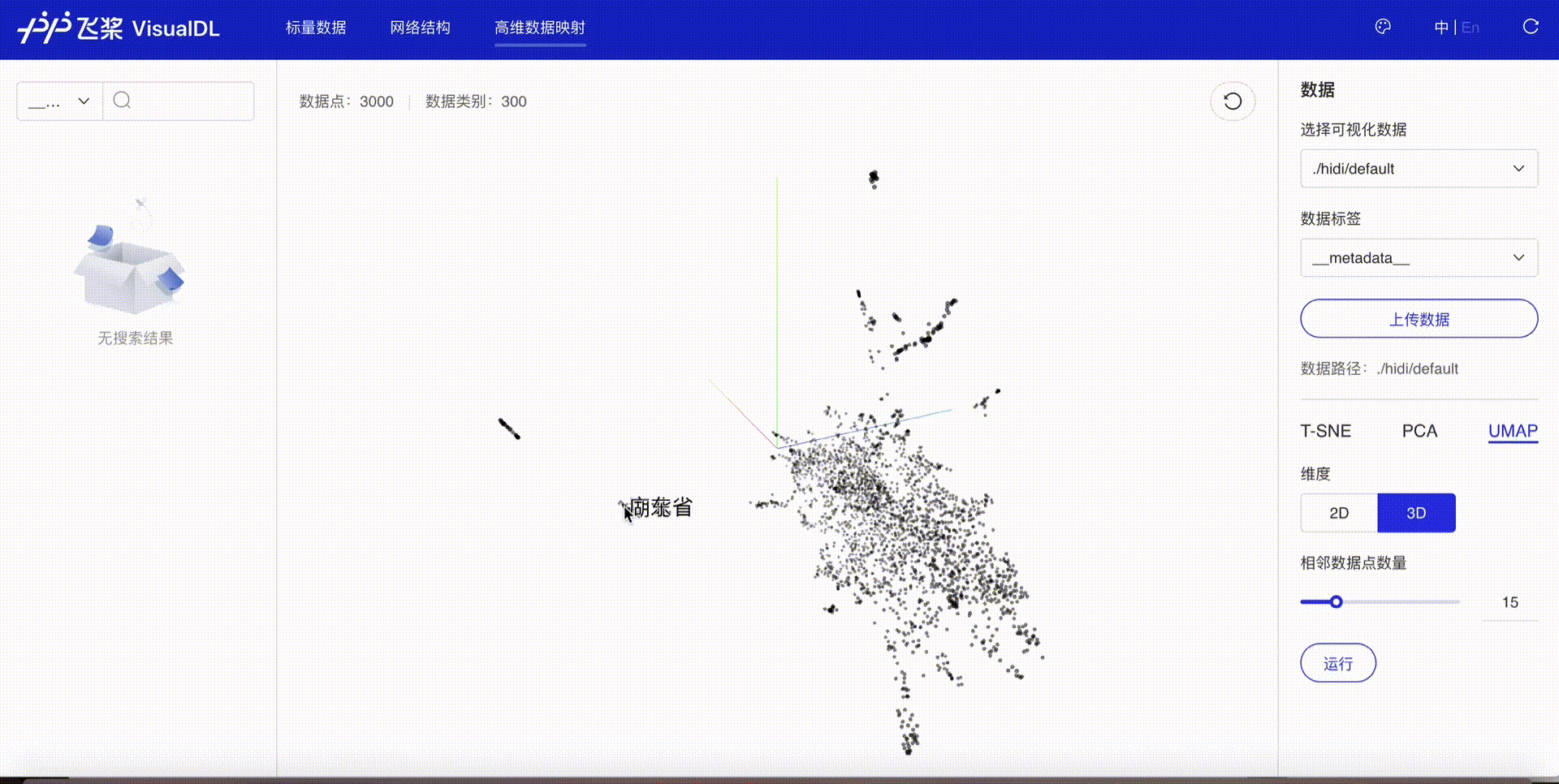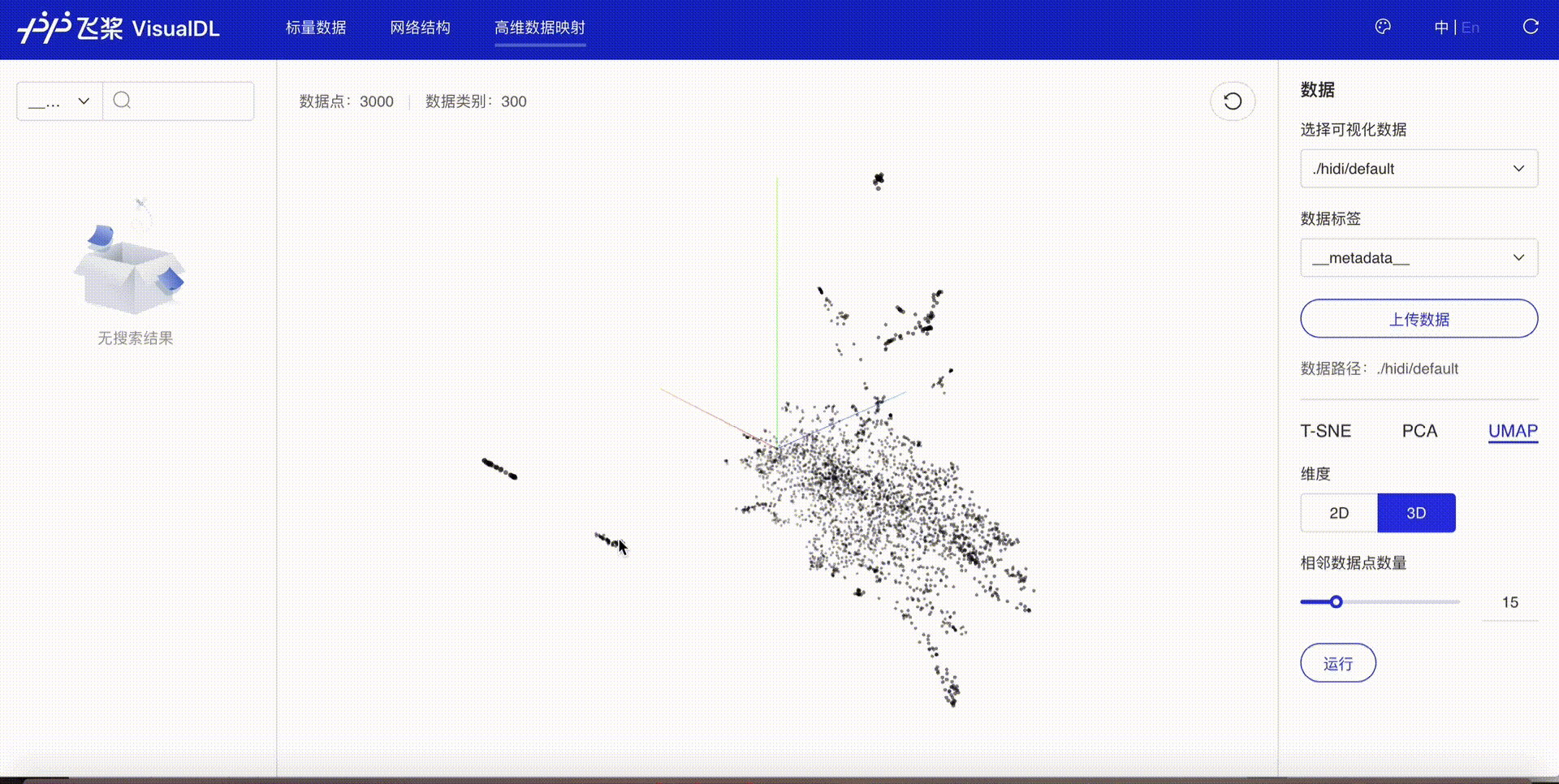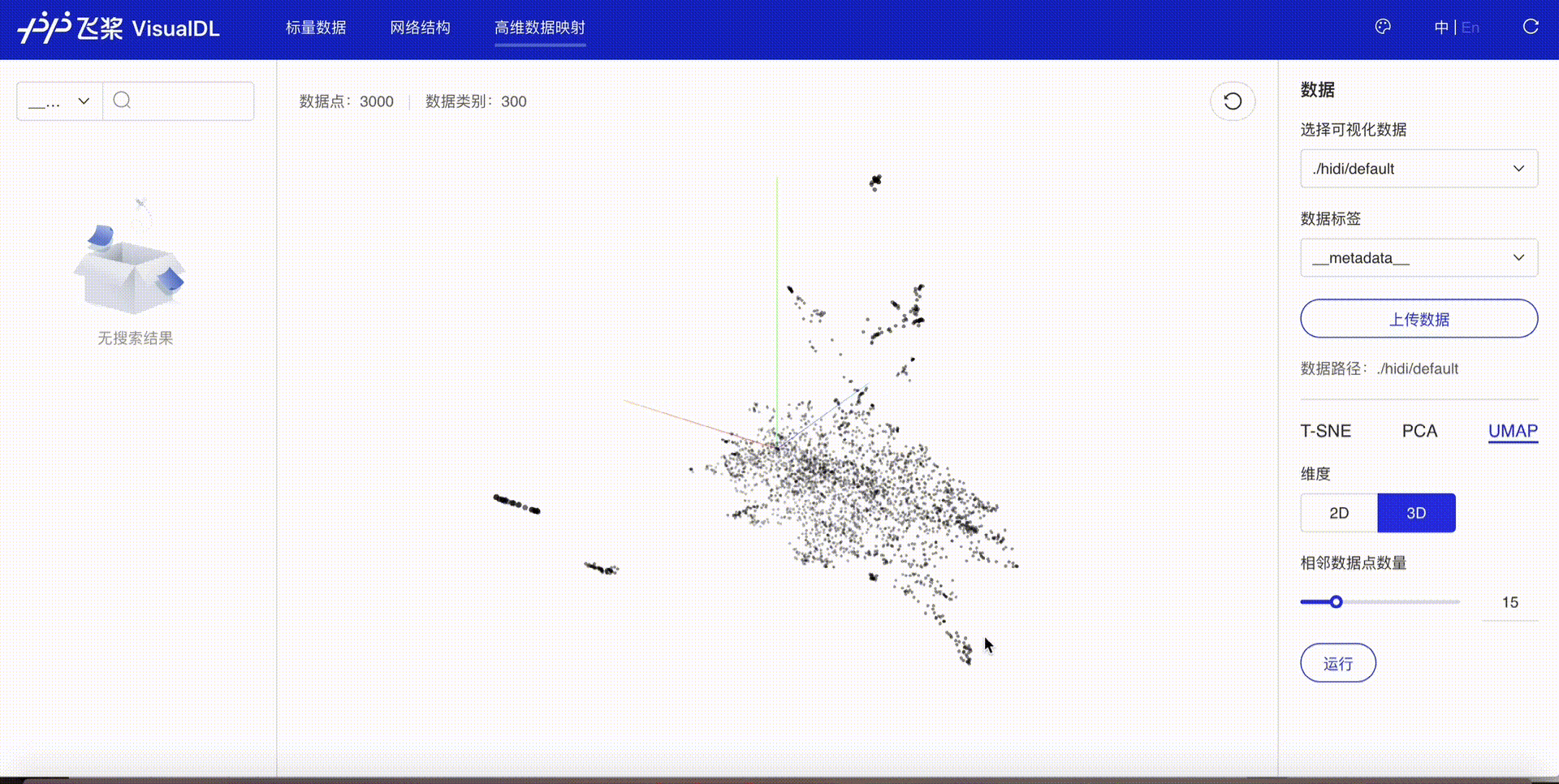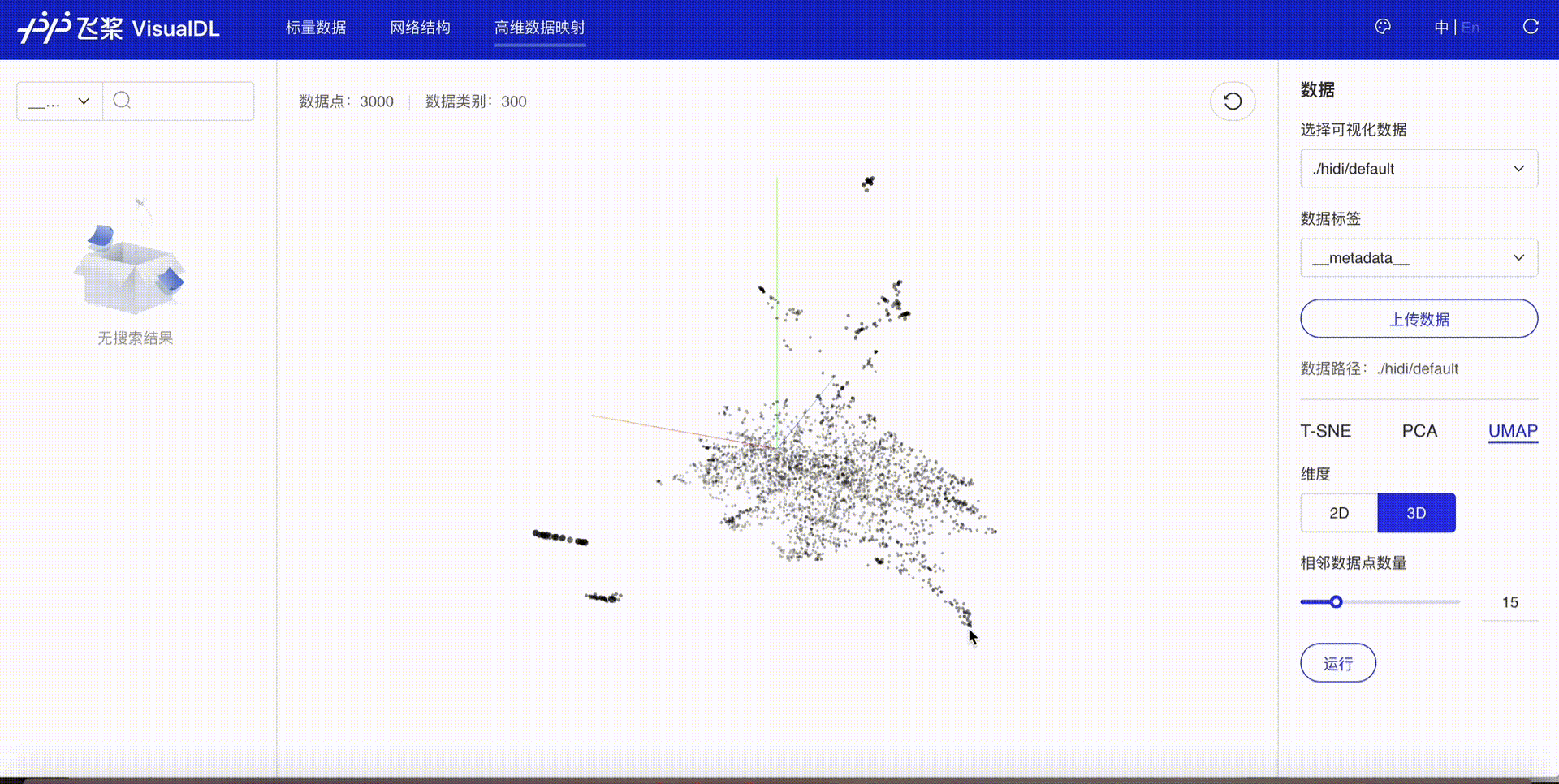
High Dimensional--数据降维组件¶
介绍¶
High Dimensional 组件将高维数据进行降维展示,用于深入分析高维数据间的关系。目前支持以下三种降维算法:
PCA : Principle Component Analysis 主成分分析
t-SNE : t-distributed stochastic neighbor embedding t-分布式随机领域嵌入
umap: uniform manifold approximation and projection for dimension reduction 流形学习降维算法
记录接口¶
High Dimensional 组件的记录接口如下:
add_embeddings(tag, labels, hot_vectors, walltime=None)
接口参数说明如下:
| 参数 | 格式 | 含义 |
| ----------- | ------------------- | ---------------------------------------------------- |
| tag | string | 记录指标的标志,如default,不能含有% |
| labels | numpy.array 或 list | 表示hot_vectors的标签,当只有一维时,labels的维度为(N, ),当有多个维度的labels时需要使用二维数组,其维度为(M, N),其中每个元素为某维度下的一维标签数组 |
| hot_vectors | numpy.array or list | 与labels一一对应,每个元素可以看作是某个标签的特征 |
| labels_meta | numpy.array or list | labels的标签,与labels一一对应,不指定则使用默认值__metadata__,当labels为一维数组时无需指定 |
| walltime | int | 记录数据的时间戳,默认为当前时间戳 |
Demo¶
下面展示了使用 High Dimensional 组件记录数据的示例,代码见High Dimensional组件
from visualdl import LogWriter
if __name__ == '__main__':
hot_vectors = [
[1.3561076367500755, 1.3116267195134017, 1.6785401875616097],
[1.1039614644440658, 1.8891609992484688, 1.32030488587171],
[1.9924524852447711, 1.9358920727142739, 1.2124401279391606],
[1.4129542689796446, 1.7372166387197474, 1.7317806077076527],
[1.3913371800587777, 1.4684674577930312, 1.5214136352476377]]
labels = ["label_1", "label_2", "label_3", "label_4", "label_5"]
# 初始化一个记录器
with LogWriter(logdir="./log/high_dimensional_test/train") as writer:
# 将一组labels和对应的hot_vectors传入记录器进行记录
writer.add_embeddings(tag='default',
labels=labels,
hot_vectors=hot_vectors)
"""
# 也可以同时提供多个label,此时`labels`为二维数组,且需要提供`labels_meta`以供前端页面选择展示不同label.
labels = [["label_a_1", "label_a_2", "label_a_3", "label_a_4", "label_a_5"],
["label_b_1", "label_b_2", "label_b_3", "label_b_4", "label_b_5"]]
# labels_meta需要和labels一一对应
labels_meta = ["label_a", "label_b"]
with LogWriter(logdir="./log/high_dimensional_test/train") as writer:
writer.add_embeddings(tag='default',
labels=labels,
labels_meta=labels_meta,
hot_vectors=hot_vectors)
"""
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
接着在浏览器打开http://127.0.0.1:8080,即可查看降维后的可视化数据。
HyperParameters--超参可视化组件¶
介绍¶
HyperParameters 以丰富的视图多角度地可视化超参数与模型关键指标间的关系,便于快速确定最佳超参组合,实现高效调参。
记录接口¶
HyperParameters 组件的记录接口与其他组件稍有不同,需要先通过add_hparams接口记录超参数(hparams_dict)和所需展示的模型度量指标名称(metrics_list)如loss、acc等,再通过调用add_scalar记录具体的模型度量指标的数值,即可记录完整的超参数可视化数据,接口说明如下:
add_hparams(hparam_dict, metric_list, walltime=None):
接口参数说明如下:
| 参数 | 格式 | 含义 |
| ----------- | ------------------- | ---------------------------------------------------- |
| hparam_dict | dict | 超参数名称及数据 |
| metric_list | list | 稍后要记录的指标名称,对应add_scalar接口中的tag参数,VisualDL通过tag对应指标数据。 |
| walltime | int | 记录数据的时间戳,默认为当前时间戳 |
Demo¶
下面展示了使用 HyperParameters 组件记录数据的示例,代码见HyperParameters组件
from visualdl import LogWriter
# 此demo演示了两次实验的超参数记录,以第一次实验数据为例,首先在`add_hparams`接口中记录
# 超参数`hparams`的数据,再标定了稍后要记录的`metrics`名称,最后通过`add_scalar`再具体
# 记录`metrics`的数据。此处需注意`add_hparams`接口中的`metrics_list`参数需要包含`add_scalar`
# 接口的`tag`参数。
if __name__ == '__main__':
# 记录第一次实验数据
with LogWriter('./log/hparams_test/train/run1') as writer:
# 记录hparams数值和metrics名称
writer.add_hparams(hparams_dict={'lr': 0.1, 'bsize': 1, 'opt': 'sgd'},
metrics_list=['hparam/accuracy', 'hparam/loss'])
# 通过将add_scalar接口中的tag与metrics名称对应,记录一次实验中不同step的metrics数值
for i in range(10):
writer.add_scalar(tag='hparam/accuracy', value=i, step=i)
writer.add_scalar(tag='hparam/loss', value=2*i, step=i)
# 记录第二次实验数据
with LogWriter('./log/hparams_test/train/run2') as writer:
# 记录hparams数值和metrics名称
writer.add_hparams(hparams_dict={'lr': 0.2, 'bsize': 2, 'opt': 'relu'},
metrics_list=['hparam/accuracy', 'hparam/loss'])
# 通过将add_scalar接口中的tag与metrics名称对应,记录一次实验中不同step的metrics数值
for i in range(10):
writer.add_scalar(tag='hparam/accuracy', value=1.0/(i+1), step=i)
writer.add_scalar(tag='hparam/loss', value=5*i, step=i)
运行上述程序后,在命令行执行
visualdl --logdir ./log --port 8080
接着在浏览器打开http://127.0.0.1:8080,即可查看超参数可视化信息。

功能操作说明¶
表格视图
表格视图可选择按照某一项排序展示。
Trial ID表示某次具体的实验名,其他正常字体展示的列名为超参数名,加粗字体展示的列名为度量指标名。
超参数和度量指标的位置可通过拖动的方式自定义。
表格视图的列宽可拖动调整。
可通过点击展开查看度量指标的变化趋势折线图。

平行坐标图
可通过悬停展示某组实验中超参数和度量指标的具体值。
可通过选中某条曲线展示此组实验中度量指标的变化趋势折线图。

散点图
可通过悬停展示某组实验中超参数和度量指标的具体值。
可通过选中某个点展示此组实验中度量指标的变化趋势折线图。

度量指标变化趋势折线图
表格视图、平行坐标图和散点图下均可查看
此处查看的度量指标变化趋势折线图同样可在
SCALARS面板下查看

超参数/度量指标范围选择
通过选择超参数或度量指标的范围以展示部分数据

下载数据
可选择CSV或TSV两种格式

Profiler--性能数据可视化组件¶
介绍¶
性能数据可视化组件用来解析飞桨框架性能分析器导出的性能数据文件,从多个角度对性能数据进行汇总分析,帮助用户诊断训练程序的性能瓶颈所在。请参考文档使用VisualDL做性能分析进行使用。

X2Paddle--模型转换组件¶
介绍¶
X2Paddle模型转换组件用来读取onnx模型,展示onnx模型的网络结构,并且帮助用户对onnx模型转换为paddle模型。用户可以对比原始的onnx模型和转换后的paddle模型结构,并且获取转换后的模型进行使用。
启动方式¶
使用该功能需要安装x2paddle和onnx>=1.6,在安装visualdl>=2.5.0时候应该会自动安装依赖库。如果需要手动安装上述依赖,可以执行命令
python -m pip install x2paddle onnx>=1.6
在命令行执行
visualdl --host 0.0.0.0 --port 8080
接着在浏览器打开http://127.0.0.1:8080,即可使用X2Paddle组件进行模型转换。
功能操作说明¶
转换onnx模型并进行下载

更换模型,选取一个新的模型进行转换

对比转换前后的模型结构

注:如果转换模型失败,将会弹出报错提示,可以拷贝模型转换失败的错误信息到X2Paddle的issue中,帮助我们更好地优化模型转换工具。
FastDeployServer--Serving可视化部署组件¶
介绍¶
FastDeployServer组件辅助用户基于FastDeploy项目使用fastdeployserver进行快速的服务化部署。主要提供模型库配置修改,服务管理监控的功能。请参考文档使用VisualDL进行Serving可视化部署进行使用。

FastDeployClient--Serving服务的客户端组件¶
介绍¶
FastDeployClient组件提供给用户对fastdeployserver服务进行访问的客户端界面,进行一键预测和可视化结果。请参考文档使用VisualDL作为fastdeployserver服务的客户端进行使用。

VDL.service¶
简介¶
VisualDL可视化结果保存服务,以链接形式将可视化结果保存下来,方便用户快速、便捷的进行托管与分享。
使用步骤¶
确保VisualDL已升级到最新版本,如未升级,请使用以下命令进行升级
pip install visualdl --upgrade
上传需保存/分享的日志/模型文件
visualdl service upload --logdir ./log \
--model ./__model__
VDL.service将返回一个URL链接,复制粘贴链接至浏览器中即可查看可视化结果

